ROLLBACK;
What makes a blockchain different from any other database?
I thought I knew the answer to this question until I tried to build one myself. Now I know a little better, but surely there are a million other little nuances out there that I don't quite fully understand. Such is technology when it's connected to cryptography and a dozen other complex solutions. Things get complicated very quickly.
I was just thinking I could piggy back off the Hive blockchain. Easy enough. Let the witnesses do all the heavy lifting and I'll just parse the custom JSON operations myself to create some kind of... derivative blockchain.

Not so fast!
Because even if I create this derivative blockchain. Who controls it? Who's allowed to add and subtract and manipulate data inside this new database? Well, that would be me. Which means it's centralized. Which is obviously... bad. At least for long term viability. It might be a good thing in the beginning when centralized control is needed to fix all the bugs and not allowing bad actors to exploit a new fledgling system.
What I have since come to realize is that a big thing that makes a blockchain a blockchain is the ability to ROLLBACK the data. And rather than this being done from inside a centralized system, computers outside the localized node that we are dealing with are allowed (and even financially incentivized) to veto bad data and not allow it into the global dataset.

A node is a node.
If we control a server we are allowed to do anything with that server that we want. We can allow bad data. We can tell our Bitcoin node to print out a billion Bitcoin and drop it into an account we control, but the rest of the network simply will not allow that, and thus the nodes are no longer in sync, and our node is running a worthless fork of the Bitcoin network that no one else will ever validate or take seriously.
So if I create a database using custom JSON, sure, the data I'm using to build the database will be pretty secure and I'll know when someone posts a JSON on Hive that they signed the transaction using a valid private key to create the corresponding correct public signature. That's all well and good.
However this does not fix the problem of me being in full control of the database or the threat of my servers getting hacked or corrupted without me even knowing about it (or by the time I do it's too late). While the data being used to seed the database is solid, it's still a centralized solution validated by only one server. It doesn't really matter that someone else could clone my database to verify that everything looks correct, because that database would not be able to modify mine, and vice versa. They could contain the exact same subsets of information and yet still be totally disconnected networks on separate forks. This was a concept I struggled with for a while when I was working on Magitek for like 12 hours a day last summer.
Luckily the Hive Application Framework that's about to come online seems tailored to fix this exact problem. It allows second layer solutions to be built on Hive with derivative consensus algorithms that aren't going to burden the Hive witnesses with hundreds of new tokens and rulesets. This will be a great addition to the ecosystem. Rather than trying to force every node to validate every transaction like Ethereum, Hive token consensus will fracture off into rulesets confirmed by different sets of separated nodes. Seems like it's going to be quite a good scaling solution in the long run, especially if we start building off-chain solutions that don't put data on the main-chain at all (or only at critical times of need).
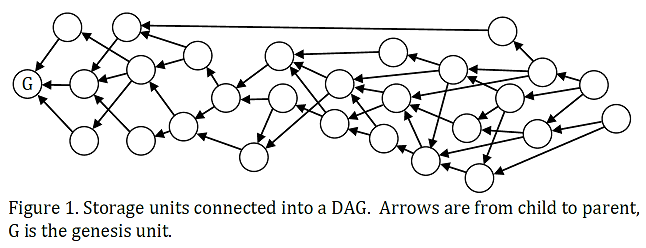
Timestamps are not linear, blockchain is.
Looking at something like DAG (directed acyclic graph) solutions we see that it is possible to allow many 'blocks' to be created at once in a kind of jumbled up order. But how do we determine the order of transactions in this case? Which block came first?
You might think 'well that's easy just use timestamps', but if the network is global time is subjective. The speed of light is not instant, and the Internet itself is even slower due to server hops and other forms of friction. What happens in America now doesn't happen in Russia for another half a second. This creates all kinds of weird edge-cases and exploits that could allow a hacker to change the order of operations to their advantage on a non-blockchain solution like a DAG.
So yeah, blockchains are inefficient and slow because we lump all the info into block and then wait for that info to be broadcast all around the world. At the same time blockchains are also very robust and easy to defend from attack. This is a game of priorities. Some applications are more suited to certain technologies, and that's great. It's all part of the great diversification we are seeing while creating economic abundance.

Where does the data come from?
This is another weird thing to think about. The data we use might be "on the blockchain" but the 'blockchain' isn't some server that someone can connect to. One must connect to an individual node and open an API channel to scrape data from the blockchain.
So if I connect to Anyx's server to get the data I'm implicitly trusting the data he's giving me and his server specifically, even though that data is supposed to come from Hive and the top 20 consensus witnesses. It's possible that it could look legit and actually be corrupted data. Thus we'd have to ping multiple Hive nodes to make sure we got the right data, or better yet run our own node with redundant security measures to make sure the data is legit.
Conclusion
Blockchains are very strange and complicated. Right when we think we've got it figured out, we learn something new that reminds us how ignorant we truly are. The complexity is vast, but this is the direction the world is headed in, so we better get crackin.
Posted Using LeoFinance Beta
Thank you. I learned about the blockchain and I what the new Hive Blockchain will look like. I appreciate the information and yes it is complicated and vast, especially for me! Were you thinking of being a witness or are you working on a dapp to run Hive? Edit: I read the link to the https://peakd.com/hive-167922/@edicted/virtual-smart-contracts-and-derivative-consensus Thanks for that background also. @cryptocharmers I am adding as a crosspost in HiveFive
I have a witness team.
@hextech
I don't shill @hextech very much because we should be doing more.
Thanks @hextech will be added. I have open witness spots. The second article made much more sense after I went back and read the first one.
Well, In the case of Hive, "slow" is actually very fast. It's something we should be very proud about, how fast transacting on the Hive blockchain is possible. I really can't imagine that in the future someone would remotely find the Hive blockchain "slow", so, it's all relative. What can you do in three seconds? Breathe once? Take a sip of your drink? That's about it.
Interesting stuff. I wasn't able to follow all of it but definitely learned a couple of things.
Just out of curiosity, is HAF going to breathe some new life into Magitek or is that on hold for the time being?
Posted Using LeoFinance Beta
It's something that I didn't think about but it's true. The data and history is all linear and not a DAG. DAGs get really complicated fairly fast as more connections happen but what happens when a block gets rolled back on a blockchain? Is it just that block or is that block just modified?
Posted Using LeoFinance Beta
The whole way crypto works is still strange to me. Gradually understanding hive and some projects built on it. At the end of the day, it feels great to be on hive.