Do you know how new phenomena are searched for at CERN’s Large Hadron Collider?
Although vacation time is slowly approaching, I am still around for a dozen of days. Then I will take a break of a few weeks, during which my online activities are expected to decrease. Due to health issues that continue after I got COVID six weeks ago, I urgently need to rest and to get some D vitamins (if you see what I mean).
This planning therefore leaves us some time for a few physics blogs. For the post of the day, I decided to start with a question. How do you think new phenomena are searched for at CERN’s Large Hadron Collider? Please try to guess the answer, and consider to share your guess in the comment section of this post (before actually reading the post).
For those reading me week after week, I very often refer to searches for new phenomena at CERN’s Large Hadron Collider (the LHC). However, I have never taken the time to properly explain how those searches are made in practice. In many of my older blogs, I only mentioned that we start from a bunch of collision events recorded by the LHC detectors, and that we end with a comparison of predictions with data that allows us to draw conclusive statements.
This comparison assesses not only how data and predictions of the Standard Model of particle physics agree with each other, but also how much space is left for any new phenomenon. Equivalently, this estimates how theories extending the Standard Model are constrained by data, and how viable they are (still relatively to current data).
However, I have never given many practical details. This is the gap that this blog tries to fill. As usual, a short summary is available in its last section below, so that readers pushed for time can get the point in 3 minutes and 23 seconds (precisely ;) ).

[Credits: Original image by Daniel Dominguez (CERN) ]
1 petabyte of data per second!
The Large Hadron Collider has been designed to produce about 600,000,000 collisions per second in the ATLAS and CMS detectors. This means that 600,000,000 times every second, a proton of the first LHC beam hits a proton of the second LHC beam in any of the detectors operating around the machine.
600,000,000… This big number is a big problem. It means that we have that amount of collisions to record every second, which would correspond to an amount of data greater by several orders of magnitude than what any data acquisition system could handle.
This indeed corresponds to a rate of 1 petabyte per second, or the equivalent of 200,000 DVDs per second. I won’t translate in terms of floppy disks, although I am sure that some my followers definitely know what they are.
The good news, however, is that we don’t actually need to record it all. This allows us instead to solely focus on collisions that are interesting for physics purposes, which yields a recording rate of only about 200 megabytes of data per second. This smaller number is in contrast manageable by electronics.
This reduction from 1 petabyte per second to 200 megabytes per second is achieved by means of an extremely fast and automatic procedure, called a triggering system. More information are given below. In addition, a lot of details are available here for the CMS detector, and there for the ATLAS detector.

[Credits: Manfred Jeitler (CERN) ]
It is all about triggers
In practice, what this triggering procedure does is to scan a given event for deposits of large amount of energy, or for particle tracks with a significant amount of momentum. All collision events giving rise to very energetic objects are considered as potentially interesting, and they are thus candidate events to be recorded.
Other events, in which protons are collided and in which only final-state particles with a small amount of energy are produced, are common and very boring. There is thus no reason to keep them on tape. Consequently, the event rate is reduced to about 100,000 events per second, which is however still too much for any existing data acquisition system.
Thanks to a powerful computing system, the pre-selected events (100,000 of them per second) can be fully reconstructed, and thus further investigated.
There are numerous outcomes for high-energy collisions. Each of them is associated with a variety of final-state products that interact differently with high-energy physics detectors, and that leave tracks and energy deposits inside them. The reconstruction process that I mentioned in the previous paragraph allows us to go from these energy deposits and tracks to actual objects like electrons, muons, etc. Please do not hesitate to check out this blog for a list and more information.
In less than 0.1 second (we must be fast, 100,000 events per second being a huge rate), we can (automatically) look whether our 100,000 interesting events are truly interesting events. Do they feature particles typical of interesting processes, within the Standard Model (so that we could study whether it really works so well) or beyond the Standard Model (to have some potential to observe some new phenomenon)? Do these events feature anything unusual?
At the end of the day (in fact, at the end of few milliseconds), 100 events out of the 100,000 pre-selected events are tagged as “definitely interesting” and recorded.
In addition, we must keep in mind that everything that has been described above occurs every single second. With this drastic reduction (100 events per second out of 600,000,000 evens per second), each of the LHC experiments records about 15,000 terabytes of data per year.
Now we can play with this data to sharpen our understanding of the universe.

[Credits: Florian Hirzinger (CC BY-SA 3.0) ]
{kind=link}
From terabytes of data to signal and background
The story of the day is far from being over. We need to provide to our 15,000 terabytes of data a small massage, so that we could extract information to be compared with predictions. Those predictions are both those inherent to the Standard Model of particle physics (we need to test it), but also those related to theories beyond it (to assess their viability and constraints).
This is where all the skills of a physicist (at least someone working on an LHC experiment) are needed. How to do that best?
A small number of the gazillions of recorded collisions must be selected for having their properties analysed. To know precisely what to select, we first need to know what we are looking for (that’s common sense, I know).
For instance, let’s assume that we are interested in the production of two top quarks (the heaviest known elementary particle) at the LHC, in a case where each of the top quarks decays into one muon, one b jet and one neutrino. I recall that a jet is a reconstructed object that indicates that the production of a highly-energetic strongly-interacting particle occured (see here for more information on how the strong interaction may change what we see in a detector). Moreover, a b jet originates from a b quark.
To write it in a short way, our signature consists in two muons, two b jets and some missing energy (neutrinos being so weakly-interacting that they escape any LHC detector invisibly). Therefore, out of the 15,000 terabytes of recorded collisions, our physics case tells us to focus only on collisions containing two muons, two b jets and some missing transverse energy.
[Credits: CERN]
As a result of this procedure, we select a good part of our top-pair signal, but not all of it. At this stage already, some events indeed escape us.
This occurs when they feature final-state objects that don’t carry enough energy, so that the reconstruction process does not yield the final state under consideration, or when some of the objects that we require are emitted in corners of the detector where the detection efficiency is small. In both cases, the effectively reconstructed event shows a final state different from that considered, so that the even is rejected.
The same as above holds for any other process of the Standard Model that would lead to the same final state. We therefore end with a bunch of selected events. A fraction of them correspond to our signal, and the rest to the background of the Standard Model.
The signal could be something that exists. In this case, we focus on the study of a process of the Standard Model, and we try to verify whether its properties match expectations. On the other hand, our events could be hypothetical ones. In this case, we study physics beyond the Standard Model, and we aim to verify whether there is an anomaly in data compared with the expectation from the Standard Model.
What about a needle in a needlestack?
In general, our signal is at this stage overwhelmed by the background. For signals of new phenomena, we could see this like looking for a needle in a haystack. However, the situation is in principle worse, so that we actually look for a specific needle in a needlestack.
There is thus a need to add criteria on the set of selected events. For instance, if we have two muons as final state objects, we could impose them to have more energy than a given threshold. Similarly, we could impose them to be almost back to back (or not too separated angularly).
The idea is to enforce selection tests that most signal events pass, and few background events pass. There are not 256 ways to know which selections to impose: we need to study the signal of interest and its properties. Moreover, this has to be done in a correlated way with the background to make sure that our tests actually kills the background more than the signal.
As an example, let’s focus on the figure below, that is useful on the context of searches for dark matter at the LHC.
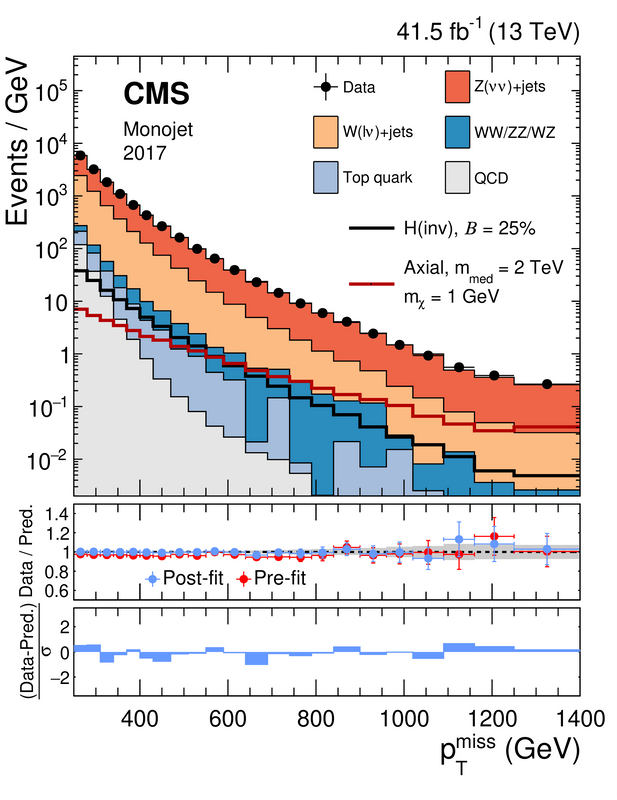
[Credits: JHEP 11 (2021) 153 (CC BY-4.0)]
Here, the CMS collaboration has selected events, out of all data that has been collected during the second operation run of the LHC. These events feature a lot of missing energy and a highly-energetic jet. This signal is a typical signal for dark matter.
Dark matter being expected to be weakly interacting with the particles of the Standard Model, once produced it escapes any LHC detector invisibly. Thanks to energy and momentum conservation, we can however detect what is invisible.
The reason is that we know the energy and momentum budget of the initial state. Conservation laws then tell us what we should get in the final state. Sometimes, we observe that energy and momentum are missing in the final state, which we indirectly attribute to weakly interacting particles like neutrinos or dark matter that leave us in a stealthy manner.
This is precisely what is reported in the upper panel of the figure above: the missing transverse energy spectrum originating from all events selected in the analysis considered. This tells us about the occurrence of events (the Y axis) featuring a small amount of missing transverse energy (on the left of the figure) and a large amount of missing energy (on the right of the figure).
Through the different colours, we stack the contributions of the different processes of the Standard Model. This consists of our background. Then we superimpose to the figure data (the black dots with their error bars).
We can see a very nice agreement between data and the Standard Model. Therefore, such a distribution can be used to constrain dark matter. The dark signal must be weak enough to be consistent with the absence of anomalies on the figure.

[Credits: The ATLAS Collaboration (CERN)]
How to build our favourite LHC analysis?
In this blog, I wanted to describe how we come up with physics analyses at CERN’s Large Hadron Collider. The machine is expected to deliver hundreds of millions of collisions per second. With 1 megabyte of data per collision (more or less), this makes it impossible for any data acquisition system.
For that reason, each detector comes with a dedicated system of triggers. Very quickly, this allows it to decide whether any given collision is interesting, or could be thrown to the bin. The goal is to reduce the rate to a hundred of collision events per second, which can be stored for further analyses.
This decision of storing or not an event is taken on the final-state products of each collision. It is based on questions such as whether there is any very energetic deposit in the detector, or whether there is any track of something carrying a large amount of momentum. We need energetic objects!
In a second step, a physics analysis, that usually takes a year or more to be realised, is put in place. The analysis focuses on a specific signal, which could be a Standard Model one (we want to study the properties of this or that particle) or a new phenomenon (do we have room for non standard effects for this or that process?).
The analysis is based on a selection of all events recorded, made from requirements constraining the particle content of the event and its properties. At the end of the day, the goal is to select, out of the terabytes of data stored, as many signal events as possible (here the signal could be a real one or a hypothetical one), and as little background events as possible.
After the selection, we verify how data and predictions match each other, and conclude. Is our signal in agreement with the Standard Model? Do we have an anomaly that could be representative of a new theory? And so on…
I stop here for today. I hope you enjoyed this blog and that you can now answer to the question raised in its title. Feel free to use and abuse of the comment section of this blog. Engagement of any form is always appreciated.
https://twitter.com/BenjaminFuks/status/1546831305442299905
The rewards earned on this comment will go directly to the people( @lemouth ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
Wow there is a need for a huge storage system there!
!1UP
Click this banner to join "The Cartel" discord server to know more.
Definitely. And with an as powerful backup system ;)
Thanks for the support!
You have received a 1UP from @gwajnberg!
@stem-curator, @vyb-curator, @pob-curator, @neoxag-curator, @pal-curator
And they will bring !PIZZA 🍕.
Learn more about our delegation service to earn daily rewards. Join the Cartel on Discord.
PIZZA Holders sent $PIZZA tips in this post's comments:
@curation-cartel(12/20) tipped @lemouth (x1)
Learn more at https://hive.pizza.
This quickly caught my attention. I don't know, but I am more than concerned. Couldn't even continue reading without dropping this.
Please get well sir, the rest is really very important. Stress has its way of affecting our immunity. I really admire your zealousness, it's rare for your kind sir, combining academics and social media. Wishing you full recovery sir.
I know. Unfortunately, my duties do not allow me to rest. University and students come first, then research and then my body ... However, my summer break is almost there (10 days to go). I will reload the batteries ;)
Congratulations @lemouth! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badges:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPI love that you’re passionate about what you do but I think your body should come first before the University, Students or research.
I wish you quick recovery…..also I love that you’re taking time off for a bit to rest, it’s expedient.
Thanks for your kind words!
This is a problem that many researchers / university lecturers has: our job is our passion, and we thus take it with one of the highest priority possible. I will however take a break tomorrow (Thursday) and enjoy a resting day at home. This is the National day in France ;)
Wow 1mb of data per collision??? So each proton holds 1/2mb? This total overload of data is comparable to the overload of sensory data that the human brain receives every second. Your sensory input equals 11 billion bits of data per second. While your brain can only process 8-9 bits of data per second. That is why you may think you placed a cup down in one spot but pick it up from a different spot. Your brain just got overloaded and it processed a different set of sensory data the second time around.
What storage medium is the data from the LHC stored on? What computer system is used to read/write this type of data. What do you think the effects quantum computing will have on the LHC? It seems to me that you would have to write and store the data into DNA if you wanted any chance at recording the entire petabyte/second of data.
is the inside the collider a vacuum when the collisions are occuring? How do you split atoms and store protons before "loading" the collider. What does the "hopper" or "tank" holding all of the particles to be collided look like?
If you took a "mini" collider with an internal vacuum state and filled it with a super fluid at room temp to then take the entire sealed collider inside of a pressure tank. Like if you supercooled your superfluid, flew it into space, loaded the collider with the sf, then pressurized the vessel around it so that your energy input would be finite and complete instead of having to put infinite energy into it to keep it cold, you'd have a "hyperspace" or "light speed" engine?
Thanks for this very nice comment, full of entertaining questions. Let me try to answer them one by one, and please do not hesitate to come back to me if further clarifications are needed.
Not really. What weights 1 MB is the electronic translation of the total numbers of tracks and hits in the detectors. Of course, the remnants of the protons after the collision play a role, but it is subdominant compared to all new final state particles produced during the collision.
Thanks for this very cool comparison with the human brain. I have never thought about it, and it is definitely a nice and relevant analogy. I will probably use it again in the future!
Data is stored on the Worldwide LHC Computing Grid, and magnetic tapes have been chosen for long-term storage. Backups are then made on different data centres from all over the world. More information can be found here and there.
I do not think much about this. Quantum computing is still barely used in high-energy physics. Some researchers (including my former student) explore possibilities, but we are still very far from any possible large scale application.
Yes. there is a pretty good vacuum, similar to what is found in the interstellar medium. In fact, there are several vacua in there with different purposes (avoiding collisions between the proton beams and gas molecules, thermal isolation, etc.)
There is a pretty large chain allowing to go from di-hydrogen molecules at rest to accelerated protons (a proton is a hydrogen nucleus). First, the di-hydrogen molecules are broken into pieces so that all protons inside are extracted. Then, the latter are accelerated progressively, by passing through various pre-accelerators, before being finally injected in the LHC.
Is this description sufficient, or do you need more information?
Here I am a bit lost with the idea. I will however try to comment on it by writing that I don’t see how practically this would work (at least to reach energies such as that at the LHC). We need a gigantic collider to be able to reach crazy speeds. This makes the space option not an option (at least today, with the technology we have).
A theory predicts something, constrained by older findings or within the frame of known models, and lays out specific expected results, then any related data would be collected, filtered, and looked into? I think... 😅
Okay, I didn't have in mind the exact steps of how the data is collected when I tried to guess above (not that I would have guessed right anyways, haha), so excuse my ignorance. :'D
Man, that's a lot of floppy disks 💾 you guys use at CERN... No wonder I can't find any in the shops anymore xD
That's totally true. However, there is also some room for the unexpected. Just in case. I didn't mention this in the blog. This is what is called "minimum bias" :)
That's OK. You are totally excused. It was more of a trick of mine to have people reacting to the blog and interacting with me ;)
Have a nice upcoming week-end!
Well your trick worked ;)
Have a wonderful upcoming week-end too, and upcoming vacation!
Thank you!
Hello @lemouth,
I start by echoing @cyprianj.
Listen to the good doctor, please :)
As for your blog: forgive me for relating what you write about CERN to my own experience every day (but then, isn't physics about life?). The problem of sorting data is something our brains tackle all the time. Even now as I write this I am filtering out data that is 'boring', that doesn't matter to me, that doesn't seem relevant to my expectations of reality.
Perhaps this is one way 'accidents' happen. We filter data based on what we know and what we expect and then the unexpected happens and we are not prepared the anomalous event.
Obviously your piece is delightful, engaging--otherwise, why would I be thinking about it? Thank you for opening a doorway into what used to seem inaccessible.
Please take care of yourself. Enjoy the D's and the family. These are the best parts of life, and the best therapy.
Warm regards,
I know... At this stage, I should simply listen to everyone. I however have so many things to do... The equation 'work = hobby = passion' makes it complicated. However, I will have a good break starting from next Friday, and I will definitely relax!
There was the comment from @killiany who also made another connection with the human brain. It is definitely a good one and it maps pretty much what is going on.
This is how analyses are thought off. However, as mentioned in my answer to @yaziris' comment, we also record so-called "minimum bias event" to give a chance to the "unexpected unexpected" to show up.
Thanks a lot for your nice words, and have a nice week-end!
The methods are thorough, complicated, and account for almost everything, no doubt about it.
This conversation however, brought into my mind an article or a lecture which I've read/seen long ago (I can't remember) about "noise" and filtering any data.
It was about how despite "filtering" any data as much as possible for example, we'd still end up with some "noise" left which we usually try to ignore and throw away. But when looked at and reassessed as part of the bigger scheme of things, it proved to be an integral and essential part of reality. And without them, the actual "interesting" data wouldn't give the whole picture or make much sense.
(I'm sorry I couldn't find it, and I probably explained it in a little messy way to make it short)
What I think @agmoore was partly talking about, is that filtering that happens by the triger mechanisms and all other consequential filtering which takes place, could be omitting some interesting "stuff".
@lemouth, you maybe needed to include more info about what "gets ignored" and why, and why the low energy events are considered not interesting.
"Minimum bias" also, is just that, "minimum".
Going into the very interesting brain analogy and the filtering of our sensory. Such "filtering" does an amazing job to give us useful data for "our needs" but it's far from the reality, in the end our perception is very limited and we detect a very limited info of what's "out there".
To sum it up and to clarify, do you think there are limitations in how the data is collected/processed in LHC that can make a "big difference" of the results?
Isn't this noise entering the uncertainties inherent to any calculation? At least this is how I see it in particle physics.
This is precisely what minimum bias event recording is aimed to. We randomly record events as soon as we get them, without any filtering. However, these events are dominated by Standard Model contributions, so that it would be very hard to seen any (rare) signal in it. It is more like a control check of the Standard Model (or its quantum chromodynamics corner dedicated to the strong interactions).
This corresponds to event configurations for which we are sure the Standard Model is correct (because we have a century of data in this regime). According to the Standard Model, we will be dominated by events originating from quantum chromodynamics interactions, and this occurs at a huge rate. Therefore, any rare phenomenon would just be invisible (i.e. well hidden in the error bars).
I do not think so. What we filter away are configurations for which we know exactly how the Standard Model behaves, and that the Standard Model is the good theory there. As no new phenomenon has been observed in the last 100 years, therefore if those are there, they must be rare.
Actually, there should be so rare that we won't notice their presence due to the typical size of the error bars on any measurement at the LHC. Therefore, even if there is new phenomenon in what we are filtering away, those will be out of our capacity of detection (and they are thus not relevant).
I hope I clarified. Otherwise feel free to come back to me. :)
This is amazing!
LOL. I don't know what you're talking about, I don't know what a floppy disk is. 😁 I am from the era of cloud storage onwards. 😏
Joking aside. I have heard that some physicists want to build an even bigger HC, but not without opposition from other physicists, like Sabrina Hossenfelder
.
In any case, this is a serious business. You guys literally help us understand the universe better.
There are arguments in favour of the next machines and arguments against them. At the end of the day, it is always a matter of costs versus benefits. Depending on who you are, what you work on, etc., then the opinion may be different. I personally think that benefits are larger than the costs.
I didn't check the video you shared (no time for this), especially after having read the abstract:
That's a non-argument. it is not because you won't fund project A that projects B+C+D+E will be funded. An existing case is when the SSC project was cancelled in the US. The money was spread elsewhere by the American congress, especially in non-science corners.
Yep. That's the argument number 1 in favour of any project: understanding the underlying mechanics of the universe :)
Congratulations @lemouth! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPBlind guess before I read the post...
I reckon through questionnaires on the perspectives, ideas, activities and outlook of the scientists working with it.
Mostly all entirely over my head but fuck you must have an interesting and fun day at work trying to solve the mysteries of the universe! 😮
I definitely have fun all day long! I consider what I do as extremely cool and super interesting. Feel free to come back to me if you have any specific question. Even if the content of the blog sounds a bit hard, I would be super happy to answer any question.
Thanks! I will do that and follow along anyway because it's fascinating! Food for thought. Which means food for creativity. And science and physics is uber cool!
I'll see you around :)
Wow es una excelente publicacion, es muy explicita, te dejo mi voto y te sigo, saludos.
Thank you for passing by! Glad to read you enjoyed my blog.