360 Degrees of Fuck

Tinkering with my database...
- Imported all 2183 posts/reblogs into it from the last 4.5 years.
- Figured how to search the body for a word
- Care to guess which one?
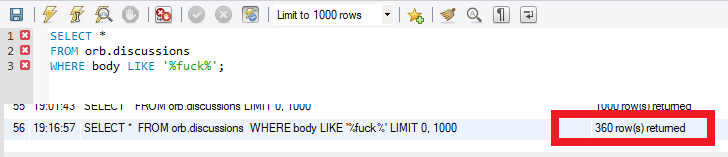
Hm I guess I've said the word 'fuck' in 360 posts.
Seems like a lot.
Maybe I have a swearing problem!
I remember when I first came to Steem there seemed to be an unspoken rule of politeness and manners. I remember in the comments of one of my posts years later someone was like, "Wait, you're allowed to curse here?"
lol
Yep... yep you certainly can.
Still not many people do.
Very unprofessional.
Not very PC!
Then again, there are no rules.
Blockchain wins.
In any case...
This is the very first time I've ever been able to search the words inside my posts. Up until know I could only link back to old posts based on the title.
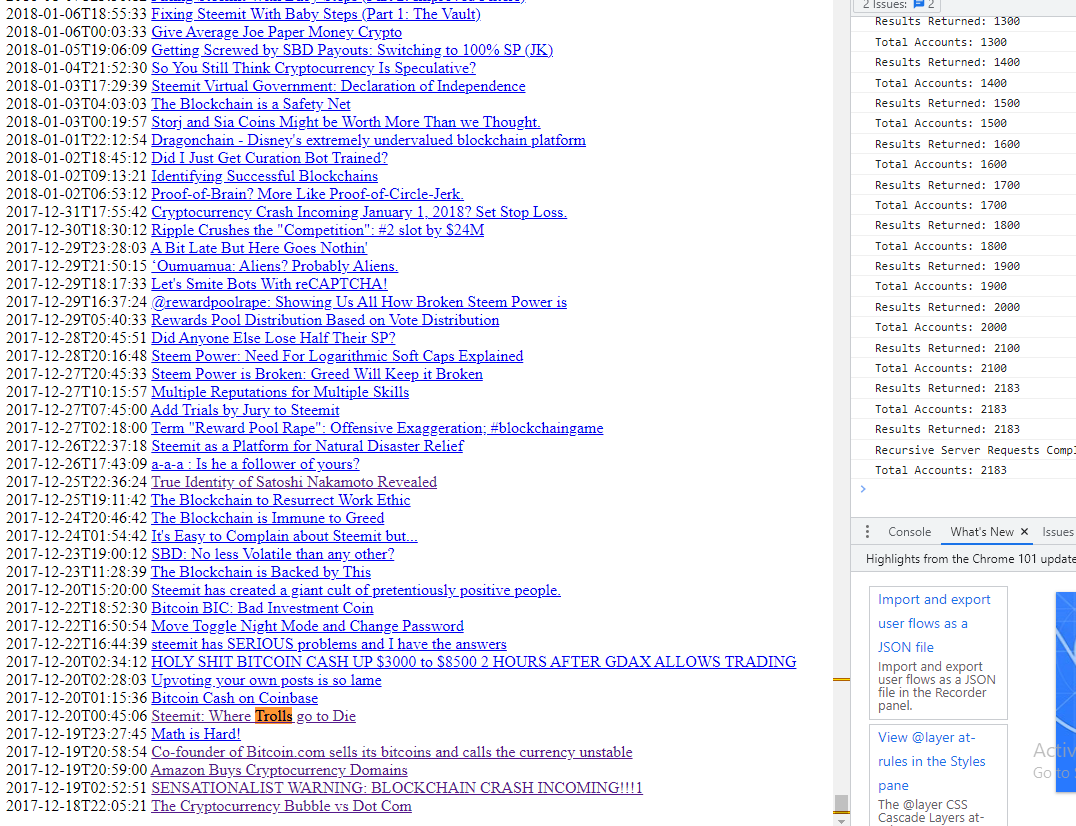
Very cool.
The original script this code was based off of was something that I built way back in 2018 when I was first learning the ropes of not only the 'Steemit' API, but also Javascript itself (and HTML/CSS). The code is HORRENDOUS! Just awful. It was seriously painful to even look at. Wow, just terrible noob code.
var client = new dsteem.Client('https://anyx.io')
lol... dsteem
I seriously can't believe this code still works after 4 years. Think about that. Amazing! Like seven hardforks and a hostile takeover and a complete rebrand and this garbage code still does exactly what I programmed it to do, which is fetch all my discussions so I can browse through them and link back to them.
I know at least one person who appreciates my aggressive referencing back to old content. I like to keep my data and thoughts linked with previous thoughts and data. What can I say.
But is it accurate?
Let's find out!
https://peakd.com/@edicted/bitcoin-is-not-traceable
Hm, yessss... totally works.
Success!
Pretty sweet.
Another cool thing?
Now that the data is persistent in my database stored directly on my SSD instead of browser RAM, I can actually close Chrome and even restart my computer without having to ask a Hive full node for all the information all over again. That's right, every time I closed the tab for this script in any way, all the data disappeared, and I had to ask a full node for 2000 posts all over again.
I seriously probably did this like... I don't know... at least 100 times over the last four years? If I requested the info once a week on average that's over 200 times. At first it wasn't that bad when I only had 500 posts. Then I had 1000 posts. Then 1500, and now over 2000. It was adding up, fam.
I feel like this is the perfect example of how inefficient blockchain tech is. Hell! This isn't even an example of how decentralized tech is inefficient... just how extremely inefficient I was being with my own code because... you know... I could afford to be. The cost was zero. In this case the entities paying for bandwidth are anyx and "unlimited" ISP service.
Data has value.
Again I think the key to blockchain sustainability is a completely revolutionary new model where all data has value. WEB2 trades the bandwidth away for 'free' and opts to seize ownership of all data and identity brands and advertising revenue on their own platform. That model isn't going to work on WEB3, yet every single dev out there and their mothers are trying to shove a square peg into a round hole. It's not going to work.
The database work I'm doing right now shows how every client can also be their own server on a public network where all the information is available. Show me a node on Hive that let's me search the body of my posts for a word and spits out the 360 answers in under 1 second. That functionality just simply does not exist because providing generic utility like that to everyone would cost way too much for an inefficient decentralized network to handle. That's fine... because I can do it locally on my own computer just fine.

The great thing about this script upgrade that I'm doing right now is that now I can branch out and start looking at other user's blogs as well. And I can branch out and look at other data like comments and transaction history. Now when I make progress the data will actually be saved in my database instead of being vaporized in RAM every time I close the tab. Not to mention how much better search functionality MySQL has vs some garbage code I wrote 4 years ago using basic array data storage in Javascript.
Why didn't I just build it correctly the first time?
Eh well, I was just learning Javascript. Also there's just not really any money in a project like this. Pretty much just for fun and experience. I'm only upgrading the code now because I've legit been using this code for over four years and the utility of being able to search through old posts has proven quite invaluable for my little blog journey I have going over here.
Also in order to connect Javascript to MySQL I needed to start learning Node.JS server script, which just seemed like a nightmare scenario... trying to learn so many things at the same time. I've made very slow progress, but I have made progress.
Look at how much more utility I have now.
This is actually crazy compared to the garbage I had before.
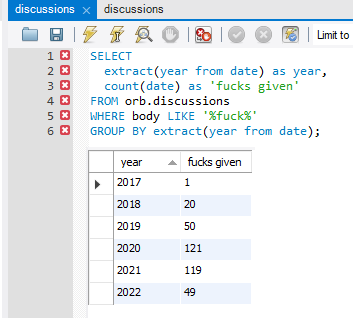
I said "fuck":
- 1 time in 2017
- 20 times in 2018 (surprising considering 2018!)
- 50 times in 2019 (getting bolder!)
- About 120 times in 2020 and 2021 (tracks).
- 49 times so far this year.
- Only need 70 more this year to hit my fuck quota.
- Oh wait 69 now because this post.
- 69
- I'm an adult.
- 420
- I'm an adult.
- 69
- Oh wait 69 now because this post.
- Only need 70 more this year to hit my fuck quota.

Oh yeah almost forgot.
I'm calling this project the Orbital Command Center.
'Orb' for short because less-is-more and it's a better name.
@urun approves.
Used to be called Steem Stake Sterilizer
Yeah I was on an alliteration kick for a second back in 2018.
Back when I was dirt poor and this was Steem and I thought I was going to put a ton of work into the project in order to mitigate the weight of upvotes on the network and how they directly correlate to the order of the trending tab and the fact that the rich get richer. This was also back when everyone was shamelessly using bid bots to buy their way into trending. Look at how far the network has come without my help. Ah well I'm here now let's see if I can actually build something useful.
It should come as no surprise that searching and filtering data on this blockchain is absurdly difficult to do. I just searched for "luna" on peakd and the results took over 5 seconds to populate. Turns out that organizing data in a helpful way is actually pretty difficult. When I searched for "fuck" and filtered my own name, the search took 10 times longer than my code and only returned 43 posts instead of 360.
Even more importantly: when I run the search locally on my own computer like this there is no internet bandwidth usage required. Having a database on the client-side can greatly cut down on the need to transfer the same information to users over and over again. How many times has peakd shown you the same blog post or the same transactions in your transaction history? Theoretically it only needs to be send to your computer one time and that's it. However, this infrastructure currently does not exist.
Why doesn't WEB2 do this?
Well, they kinda do: they use a technology called "cookies". You've probably heard of them, but if not this is just data stored in your browser that WEB2 servers can use to store information and track what you are doing. They can't really force you to run a database like I'm suggesting in this post, but then again they don't need to.
The real reason why WEB2 would never do something like this is that databases and node servers are a web of permissions and certifications. A WEB2 service would never give anyone full access to the system. That would be disastrous! Also, on an intrinsic level, WEB2's entire business model is one where they monetize massive quantities of data. They literally can't afford to give that data away for free, and the APIs reflect that.
On WEB3 this is totally the opposite. Everything is public; everything is viewable. Jesus, we even store every single password directly on chain! How insane is that?
Seriously though...
Think about how crazy this is compared to WEB2. Not only do we store passwords directly on chain for anyone to see, but also if we didn't store public keys on chain the entire system wouldn't even work. There are many foundations of WEB3 that are completely contrary to WEB2, which is why it's so absurd that so many devs out there keep projecting WEB2 tactics onto WEB3 because they simply do not know any better. We are still very very early adopters; this is obvious from a developer's perspective. Encryption is magic, wielded by math ninjas.

The end-game goal of this Orb project is to finally build out my reputation system that I was theory-crafting years ago (2018 ew). By allowing users to participate in this reputation system, and then combining data from multiple users, we can create new feeds and new ways to curate data on the chain.
The reputation system (if it works correctly) can also be used to create an entire suite of dapplications. For example, if p2p reputation is implemented, all of a sudden I could build the Soul project (p2p loans based off of reputation) & the iRate network that allows trusted users to review products/services. The key to reviews is to review the reviewers themselves and make sure they aren't providing useless information (and paying them for good information).

Paying our fair share.
Paying for data/bandwidth could NEVER work in WEB2. That's why no one is talking about it now. Everyone assumes we need to provide free service because everyone expects free service because of the WEB2 business model that everyone knows and "loves".
That is not how WEB3 works. We now have direct access to not only a native currency but also with something like Hive we can create income & payment streams in real time. We absolutely can micro-charge an account three cents because they used a lot of bandwidth.
The key to this WEB2 >> WEB3 transition is a user experience where the user doesn't even realize they're being charged when they join the network. That means logging in with a username and password and email account recovery (custodian holds the private keys until they transition to WEB3). We are already developing this tech across multiple platforms. Splinterlands and Leofinance and the Speak network are all building this exact user experience independently because it is so important.
The second part of this transition (super ironic) requires that we allow users to go into debt. Accounts will be charged for data usage, but their balances will be allowed to go negative up to a certain point. It is in this way that the service will appear like it is a free WEB2 thing when it reality this is all a trick of WEB3. Because users actually build value within a WEB3 ecosystem (example: upvotes), this debt can also be paid off in the background without the noobs having any idea what is going on until they figure it out like a year later. These small baby-steps are key to lowering the learning curve for WEB3.

Again, this is super ironic, but the future of crypto is a pyramid of trust. Using Hive as a template, at the top of this trust-pyramid are the witnesses. We trust that the data extracted from their nodes is the truth. We can verify this trust by pinging multiple full-nodes for the same piece of data or (even better) by running our own node to verify the data we are getting is the truth.
However, I believe the end game is to flush out the pyramid and allow "second layer" users to create peer-to-peer solutions that allow us to scale up. For example, the database I'm building right now would be an example of this second layer. I received the data from layer-one (in this case @anyx or @deathwing full node) and then I'm manipulating, organizing, and filtering the data I receive to make it more valuable. In theory, I could then sell the data I farm to the layers under myself using the micro-charging debt system.
This is a crude example of how we can outsource data and resources so that all the burden of bandwidth and computer power does not fall on the top 20 witnesses in a centralized manner. The beauty of Hive is that the max blocksize is only 65 kilobytes. Imagine how absurdly easy it would be to share data and organize it in a peer-to-peer torrenting system where the data has actual value (even if it's only pennies, those pennies add up).
More importantly, a strategy like this also completely eliminates the Sybil and DDOS attacks that WEB2 suffers from. If everyone has to pay for data instead of getting it for free, a DDOS attack becomes impossible because the person getting attacked is making money off of the attack.
Remember what happened during the Steem hostile takeover?
Same story. With innovative solutions, WEB3 can monetize WEB2 attacks against it and actually profit from the attack. On a technical level, this is an insane development. Alas, again, the infrastructure just really doesn't exist yet. But it will get built eventually. The value of such things is simply too great.
Conclusion
It's nice to get back into programming on a small project like this. Make no mistake, my Magitek project is still there but I needed a less daunting task in order to jump back into the programming game. I'm excited to get back to it now that I have a database up and running.
I'll be damned if I'm gonna let a crippling recession keep me down.
Bear markets are for building, and I'm ready to buidl.
Posted Using LeoFinance Beta
49 2022 fucks is way above the 32 fuck annual fuck doubling curve my friend. I hate to break it to you, but you are entering mega fuck bubble territory.
Of course, this isn't fucking fuckancial advice. Your fucking journey is your own.
approve it!
This killed me. Sick database of your posts! I wanna do something like that for mine but I don't even know where to start.
Posted Using LeoFinance Beta
Hopefully I can build it out enough that anyone can clone it.
I may import your posts and a few other people like taskmaster during testing.
That would be cool - let me know if you need anything from me.
Posted Using LeoFinance Beta
I would be interested in that code too, or ideally in a tool, that can be accessed via a web-browser.
Somewhat defeats the purpose of decentralizing the information but that's the price of convenience. I definitely envision making some kind of node that's accessible in addition to the decentralized client-side database.
Came to say this!
I think the number of fucks you give is directly tied to the price, and this is one of your best fucking posts.
There, I never say that word or at least rarely, but I giggled at your post!
Really good to see you working on programming skills!
Posted Using LeoFinance Beta
When one really compares web3 to what we were getting with web2 projects, it is difficult not to get angry and feel ripped off
Posted Using LeoFinance Beta
How many times have your written "fart"?
lol wut?
Seems like a lot... it's deep dive time.
Yep no dice
'Farther' has 'fart' in it.
looks like I've only said fart maybe 2 times?
3 times
lets get those receipts!
https://peakd.com/@edicted/drugwars-breakeven-and-pharma-3
strike one
https://peakd.com/@edicted/making-some-progress
strike two
https://peakd.com/@edicted/new-defi-development-honeypot-honeyswap-and-honey-on-hiveblockchain
strike three
shit i didnt even write this one
congrats you broke the game
zero times
Allowing users to go into debt sounds like a fairly scary idea. I wonder how many people just opt out of that type of system instead though.
Posted Using LeoFinance Beta
Why does it sound scary?
They don't even have to pay it back.
If they go too far negative their account simply stops working.
Also something like this doesn't need to exist when crypto goes mainstream.
This is simply part of the transition from web2 to web3
I guess that would work but I feel that many users might want to see some earnings at the start for motivation and the debt issue might remove that.
Posted Using LeoFinance Beta
Hooray for web 3 and for folks like yourself who have the skills to take advantage of what it has to offer for the common good!
Posted Using LeoFinance Beta
Great work. That looks like a useful project I should create in Python. :)
Posted Using LeoFinance Beta
fukn buidl
!PGM
BUY AND STAKE THE PGM TO SEND A LOT OF TOKENS!
The tokens that the command sends are: 0.1 PGM-0.1 LVL-2.5 BUDS-0.01 MOTA-0.05 DEC-15 SBT-1 STARBITS-0.00000001 BTC (SWWAP.BTC)
Discord
Support the curation account @ pgm-curator with a delegation 10 HP - 50 HP - 100 HP - 500 HP - 1000 HP
Get potential votes from @ pgm-curator by paying in PGM, here is a guide
I'm a bot, if you want a hand ask @ zottone444
You need a swear-bot! If you curse in a post someone could comment like a pizzabot, but you wouldn't get token; they would be taken away from you. In a virtual swear jar.
Posted Using LeoFinance Beta